Snowflake is a Fully Managed cloud data platform. This means that it provides everything you need to build your data solution, such as a full-feature data warehouse. It is cloud-agnostic and most importantly you can even replicate between the clouds.
The architecture comprises a hybrid of traditional shared-disk and shared-nothing architectures to offer the best of both.
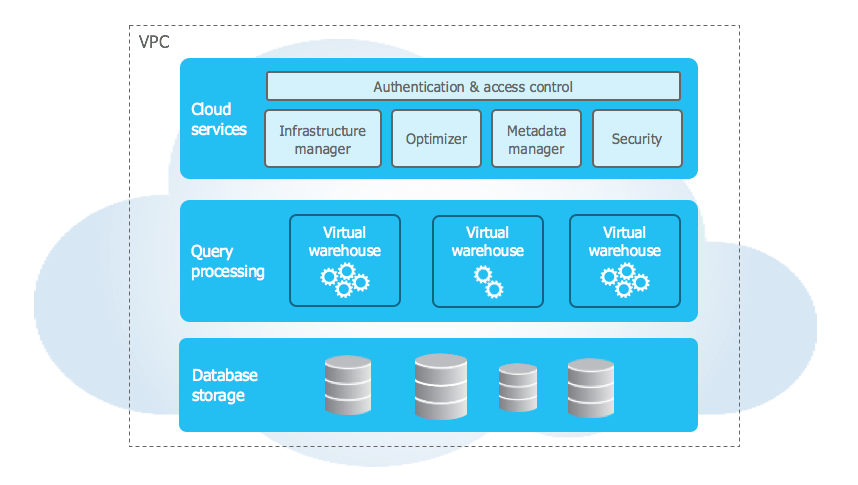
The storage layer organizes the data into multiple micro partitions that are internally optimized and compressed. Data is stored in the cloud storage (storage is elastic) and works as a shared-disk model thereby providing simplicity in data management. The data objects stored by Snowflake are not directly visible nor accessible by customers; they are only accessible through SQL query operations run using Snowflake. As the storage layer is independent, we only pay for the average monthly storage used.
Compute nodes (Virtual Warehouse) connect with the storage layer to fetch the data for query processing. These are Massively Parallel Processing (MPP) compute clusters consisting of multiple nodes with CPU and Memory provisioned on the cloud by Snowflake. These can be started, stopped, or scaled at any time and can be set to auto-suspend or auto-resume for cost-saving.
Cloud Services Layer handles activities like authentication, security, metadata management of the loaded data, and query optimization
Data is automatically divided into micro-partitions and each micro-partition contains between 50 MB and 500 MB of uncompressed data. These are not required to be defined upfront. Snowflake stores metadata about all rows stored in a micro-partition.Columns are stored independently within micro-partitions, often referred to as columnar storage. Refer this for more details.
In addition to this, you can manually sort rows on key table columns, however, performing these tasks could be cumbersome and expensive. This is mostly useful for very large table
No comments:
Post a Comment